前言:
立个flag,从今天开始学习Python ( ̄︶ ̄)↗,希望自己能坚持下去。
那些最好的程序员不是为了得到更高的薪水或者得到公众的仰慕而编程,他们只是觉得这是一件有趣的事情。(扯淡) ——Linux 之父 LinusTorvalds
Python 的设计理念是 “优雅”、“明确”、“简单”。
人生苦短,我用Python
关于python的介绍就不多说了,只记录下一些重要的部分,在系统的学习之前先说下python语言的一些特点。
一、Python3 基础语法:
1、编码:
默认情况下,Python 3源码文件以utf-8编码,所有字符串都是 unicode 字符串。 当然也可以为源码文件指定不同的编码:
# -*- coding:UTF-8 -*-# -*- coding:cp-1252 -*-2、python保留字:
保留字即关键字,我们不能把它们用作任何标识符名称。Python 的标准库提供了一个 keyword 模块,可以输出当前版本的所有关键字:
>>> import keyword
>>> keyword.kwlist
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except',
'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise',
'return', 'try', 'while', 'with', 'yield']3、标识符:
- 第一个字符必须是字母或下划线
_。 - 标识符对大小写敏感。
- 在 Python 3 中,可以用中文作为变量名。
4、注释:
Python中单行注释以 # 开头,Python中单行注释以#开头,多行注释用三个单引号(''')或者三个双引号(""")将注释括起来。
例:
#!/usr/bin/python3
# 第一个注释
print ("Hello, Python!") # 第二个注释5、行与缩进:
python最具特色的就是使用缩进来表示代码块,不需要使用大括号
{}。缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数。实例如下:
if True:
print ("True")
else:
print ("False")以下代码最后一行语句缩进数的空格数不一致,会导致运行错误:
if True:
print ("Answer")
print ("True")
else:
print ("Answer")
print ("False") # 缩进不一致,会导致运行错误6、多行语句:
Python 通常是一行写完一条语句,但如果语句很长,我们可以使用反斜杠\来实现多行语句,例如:
total = item_one + \
item_two + \
item_three在 [], {}, 或 () 中的多行语句,不需要使用反斜杠(),例如:
total = ['item_one', 'item_two', 'item_three',
'item_four', 'item_five']7、同一行使用多条语句:
Python可以在同一行中使用多条语句,语句之间使用分号;分割,以下是一个简单的实例:
import sys; x = 'runoob'; sys.stdout.write(x + '\n')输出结果为:
runoob8、导入模块:
- 在 python 用
import或者from...import来导入相应的模块。 - 将整个模块(somemodule)导入:
import somemodule - 从某个模块中导入某个函数:
from somemodule import somefunction - 从某个模块中导入多个函数:
from somemodule import firstfunc, secondfunc, thirdfunc - 将某个模块中的全部函数导入:
from somemodule import *
9、输入输出:
执行下面的程序在按回车键后就会等待用户输入:
input("请输入:")
用户按下 enter 键时,程序将退出。
print 默认输出是换行的,如果要实现不换行需要在变量末尾加上 end="": ,引号里可以添加符号用来分隔数据。
例:

第一个 Python3 程序:
#!/usr/bin/python3
print("Hello, World!")#!/usr/bin/python :指定用什么解释器运行脚本(如果是python2就用#!/usr/bin/python2,python3同理)和解释器所在的位置,如果解释器没有装在/usr/bin/目录,改成其所在目录就行了,或者更通用的方法是(自动寻找解释器):
#!/usr/bin/env python将以上代码保存在 hello.py 文件中并使用 python 命令执行该脚本文件。
python hello.py以上命令输出结果为:
🆗,这些基本的东西说完了,开始正式学习。
第一节:变量和字符串
首先:Python 每个语句结束可以不写分号 ;, 如 print('hello') 打印 hello
1、变量
因为之前学过编程语言,变量就不多说了。需要注意的是,Python 对大小写敏感,也就是说 “a” 和 “A” 会是两个不同的变量。
2、字符串
1、基本介绍:
单引号 ''或者双引号 "" 都可以,再或者 ''' ''' 三引号,其中三引号被用于过于长段的文字或者是说明,只要是三引号不完你就可以随意换行写下文字。
- 字符串直接能相加,如:
运行结果:str1 = 'hi' str2 = 'hello' print(str1 + str2)
hi jaybo- 字符串相乘,如:
string = 'bang!' total = string * 3
打印 total :
bang!bang!bang!2、字符串的分片与索引:
字符串可以通过 string[n] 的方式进行索引和分片。
字符串的分片实际可以看作是从字符串中找出来你要截取的东西,复制出来一小段你要的长度,存储在另一个地方,而不会对字符串这个源文件改动。分片获得的每个字符串可以看作是原字符串的一个副本。
先看下面这段代码:
name = 'My name is Mike'
print(name[0])
'M'
print(name[-4])
'M'
print(name[11:14]) # from 11th to 14th, 14th one is excluded
'Mik'
print(name[11:15]) # from 11th to 15th, 15th one is excluded
'Mike'
print(name[5:])
'me is Mike'
print(name[:5])
'My na'解释: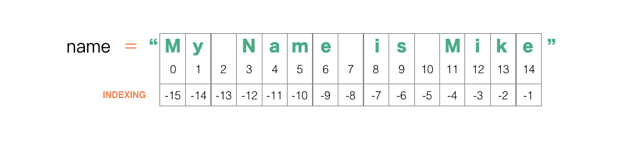
: 两边分别代表着字符串的分割从哪里开始,并到哪里结束。
以 name[11:14] 为例,截取的编号从第11个字符开始,到位置为14但不包含第14个字符结束。
而像 name[5:] 这样的写法代表着从编号为5的字符到结束的字符串分片。
相反,name[:5] 则代表着从编号为0的字符开始到编号为5但不包含第5个字符的字符分片。可能容易搞混,可以想象成第一种是从5到最后面,程序员懒得数有多少个所以就省略地写。第二种是从最前面到5,同样是懒得写0,所以就写成了 [:5] 。
3、尝试:
num = 1
string = '1'
print(num + string)上面代码将出错!
解释:整数型不能和字符串直接相加。可以先把该字符串转为整数型,再相加,即 int(string)
num = 1
string = '1'
print(num + int(string))4、 字符串的方法:
这里以replace方法为例
- 很多时候你使用手机号在网站注册账户信息,为了保证用户的信息安全性,通常账户信息只会显示后四位,其余的用 * 来代替,我们试着用字符串的方法来完成这一个功能。
输入代码:
phone_number = '1386-666-0006'
hiding_number = phone_number.replace(phone_number[:9],'*' * 9)
print(hiding_number)我们使用了一个字符串方法 replace()进行“遮挡”。replace 方法的括号中,第一个 phone_number[:9] 代表要被替换掉的部分,后面的 '*' * 9 表示将要替换成什么字符,也就是把 * 乘以9,显示9个 * 。
你会得到这样的结果:*********0006
第二节:函数
1、创建函数
Python 中所谓的使用函数,就是把你要处理的对象放到一个名字后面的括号里。简单来说,函数就是这么使用的,往里面塞东西就可以得到处理结果。这样的函数在 Python 中还有很多。
这里面先介绍几个常见的词:
def(即 define,定义)的含义是创建函数,也就是定义一个函数。arg(即 argument,参数)有时你还能见到这种写法:parameter,二者都是参数的意思但是稍有不同,这里不展开说了。return即返回结果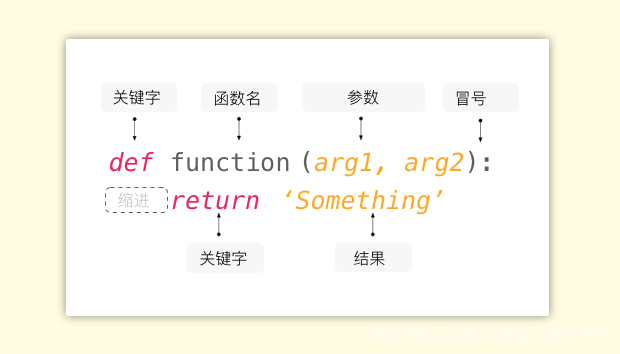
- 举个例子:
把摄氏度转化定义为函数 fahrenheit_Converter() ,那么将输入进去的必然是摄氏度(Celsius)的数值,我们把 C 设为参数,最后返回的是华氏度(fahrenheit)的数值,我们用下面的函数来表达,输入代码:
def fahrenheit_converter(C):
fahrenheit = C * 9/5 + 32
return str(fahrenheit) + '˚F' 注:计算的结果类型是float,不能与字符串'˚F'相合并,所以需要先用str()函数进行转换。
输入完以上代码后,函数定义完成,那么我们开始使用它。我们把使用函数这种行为叫做“调用”(call)。
下面这段代码意味着——“请使用摄氏度转换器将35摄氏度转换成华氏度,将结果储存在名为 C2F 的变量并打印出来。”这样我们就完成了函数的调用同时打印了结果。
C2F = fahrenheit_converter(35)
print(C2F)2、传递参数与参数类型
前面说了关于函数定义和使用,在这一节我们谈论一些细节但是重要的问题一一参数。对于在一开始就设定了必要参数的函数来说,我们是通过打出函数的名称并向括号中传递参数实现对函数的调用(call),即只要把参数放进函数的括号中即可,就像是这样:
fahrenheit_converter(35)
fahrenheit_converter(15)事实上,传递参数的方式有两种:
- 位置参数
- 关键词参数
例:
def trapezoid_area(base_up, base_down, height):
return 1/2 * (base_up + base_down) * height接下来我们开始调用函数。
trapezoid_area(1,2,3)不难看出,填入的参数 1,2,3 分别对应着参数 base_up,base_down 和 height。 这种传入参数的方式被称作为位置参数。
接着是第二种传入方式:
trapezoid_area(base_up=1, base_down=2, height=3)更直观地,在调用函数的时候,我们将每个参数名称后面赋予一个我们想要传入的值。这种以名称作为一一对应的参数传入方式被称作是关键词参数。
避免混乱的最好方法就是先制造混乱,我们试着解决一个更复杂的问题,按照下面几种方式调用函数并打印结果:
trapezoid_area(height=3, base_down=2, base_up=1) # RIGHT!
trapezoid_area(height=3, base_down=2, 1) # WRONG!
trapezoid_area(base_up=1, base_down=2, 3) # RIGHT!
trapezoid_area(1, 2, height=3) # RIGHT!- 第一行的函数参数按照反序传入,因为是关键词参数,所以并不影响函数正常运作;
- 第二行的函数参数反序传入,但是到了第三个却变成了位置参数,遗憾的是这种方式是 错误的语法,因为如果按照位置来传入,最后一个应该是参数 height 的位置。 但是前面 height 已经按照名称传入了值3,所以是冲突的。
- 第三行的函数参数正序传入,前两个是以关键词的方式传入,最后一个以位置参数传入,这个函数是可以正常运行的;
- 第四行的函数参数正序传入,前两个是以位置的方式传入,最后一个以关键词参数传入,这个函数是可以正常运行的。
2.1 认识一个新的函数一 “open”
这个函数使用起来很简单,只需要传入两个参数就可以正常运转了:文件的完整路径和名称,打开的方式。
如果是 Windows 用户,应该像这样写你的路径:
file = open('C:/Users/smk/Desktop/text.txt','w')
file.write('hello world!')
file.close()
这段代码打开了桌面上的 file.txt 文件,并写入了 “Hello World” ,w 代表着如果桌面上有 file.txt 这个文件就直接写入 “hello world” ,如果没有 file.txt 这个文件就创建一个这样的文件。
但此时数据只写到了缓存中,并未保存到文件!文件需要close()方法关闭这个文件即可将缓存中的数据写入到文件中。
第三节:循环与判断
1、逻辑判断一一True & False
之前学过编程语言,这里就不多写了。
2、成员运算符与身份运算符
成员运算符和身份运算符的关键词是 in 与 is。把 in 放在两个对象中间的含义是,测试前者是否存在于 in 后面的集合中。
例:
album = ['Black Star','David Bowie',25,True]接下来我们使用 in 来测试字符串 “Black Star” 是否在列表 album 中。如果存在则会显示 True,不存在就会显示 False 了:
'Black Star' in album接下来再来说 is 和 is not,它们是表示身份鉴别的布尔运算符,in 和 not in 则是表示归属关系的布尔运算符号。
在 Python 中任何一个对象都要满足身份(Identity)、类型(Type)、值 (Value)这三个点,缺一不可。is 操作符号就是来进行身份的对比的。
例:
the_Eddie = 'Eddie'
name = 'Eddie'
the_Eddie is name当两个变量一致时,经过 is 对比后会返回 True。
3、条件控制
条件控制其实就是 if…else 的使用。先来看下条件控制的基本结构: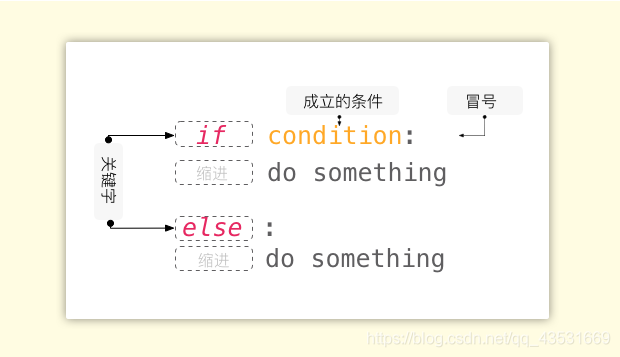
例:
def account_login():
password = input('Password:')
if password == '12345':
print('Login success!')
else:
print('Wrong password or invalid input!')
account_login()
account_login()- 第1行:定义函数,并不需要参数;
- 第2行:使用 input 获得用户输入的字符串并储存在变量 password 中;
- 第3、4行:设置条件,如果用户输入的字符串和预设的密码12345相等时,就执行打印- 文本‘Login success!’;
- 第5、6行:反之,一切不等于预设密码的输入结果,全部会执行打印错误提示,并且再次调用函数,让用户再次输入密码;
- 第7行:运行函数;
- 第8行:调用函数。
如果 if 后面的布尔表达式过长或者难于理解,可以采取给变量赋值的办法来储存布尔表达式返回的布尔值 True 或 False。因此上面的代码可以写成这样:
def account_login():
password = input('Password:')
password_correct = password == '12345' #HERE!
if password_correct:
print('Login success!')
else:
print('Wrong password or invalid input!')
account_login()
account_login()多条件判断同样很简单,只需在 if 和else 之间增加上 elif,用法和 if 是一致的。就不多说了。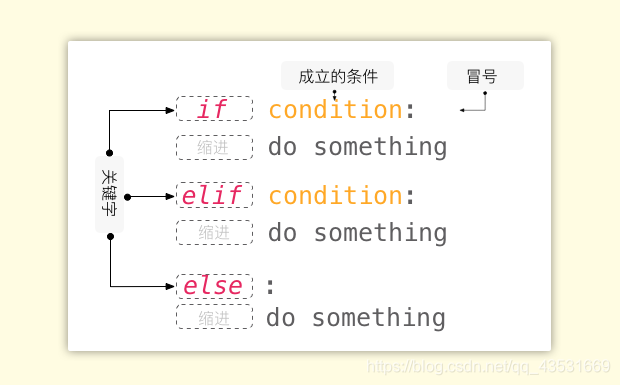
4、循环(Loop)
- for 循环
例:
for every_letter in 'Hello world':
print(every_letter)得到这样的结果:
H
e
l
l
o
w
o
r
l
d解释:
for 是关键词,后面的为变量名称,至于变量起什么名字自己定,但不要和关键词重名。
在关键词 in 后面所对应的一定是具有“可迭代的”,或者说是像列表那样的集合形态的对象,即可以连续地提供其中的每一个元素的对象。

为了更深入了解 for 循环,我们来举个例子:
for num in range(1,11): #不包含11,因此实际范围是1~10
print(str(num) + ' + 1 =',num + 1)运行结果:
这里用到了内置函数一range。我们只需要在 range 函数后面的括号中填上数字,就可以得到一个具有连续整数的序列。
把 for 和 if 结合起来使用
代码如下:
songslist = ['Holy Diver', 'Thunderstruck', 'Rebel Rebel']
for song in songslist:
if song == 'Holy Diver':
print(song,' - Dio')
elif song == 'Thunderstruck':
print(song,' - AC/DC')
elif song == 'Rebel Rebel':
print(song,' - David Bowie')实现了这样一个功能:歌曲列表中有三首歌“Holy Diver, Thunderstruck, Rebel Rebel”,当播放到每首时,分别显示对应的歌手名字“Dio, AC/DC, David Bowie”。
5、嵌套循环
打印九九乘法表:
还记得当初学C语言的时候打印一个九九乘法表需要的代码起码有十几二十行吧,但是在python里却只需要三行!!
for i in range(1,10):
for j in range(1,10):
print('{} X {} = {}'.format(i,j,i*j))运行结果: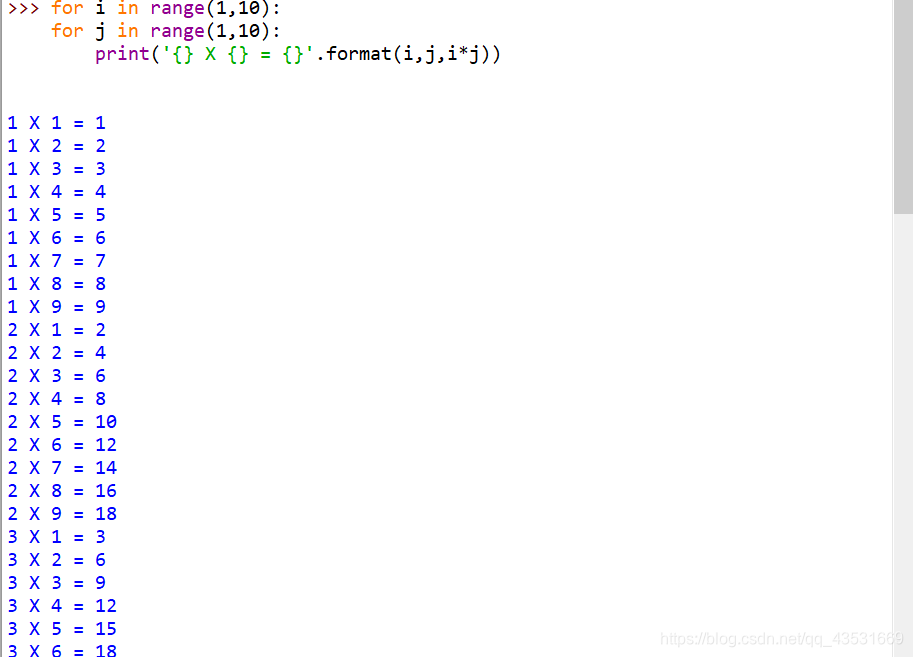
6、While 循环
语法:
用法就不举例了。
第六节:数据结构
正如在现实世界中一样,直到我们拥有足够多的东西,才迫切需要一个储存东西的容器,这些储存大量数据的容器,在 Python 称之为内置数据结构。
Python 有四种数据结构,分别是:列表、字典、元组,集合。每种数据结构都有自己的特点,并且都有着独到的用处。
1、列表(list)
先从列表开始,列表具有的最显著的特征是:
- 列表中的每一个元素都是可变的;
- 列表中的元素是有序的,也就是说每一个元素都有一个位置;
- 列表可以容纳 Python 中的任何对象。
- 列表中的元素是可变的,这意味着我们可以在列表中添加、删除和修改元素。
列表中的每一个元素都对应着一个位置,我们通过输入位置而查询该位置所对应的值,试着输入:
Weekday = ['Monday','Tuesday','Wednesday','Thursday','Friday']
print(Weekday[0])结果为;
第三个特征是列表可以装入 Python 中所有的对象:
all_in_list = [
1, #整数
1.0, #浮点数
'a word', #字符串
print(1), #函数
True, #布尔值
[1,2], #列表中套列表
(1,2), #元组
{'key':'value'} #字典
]
for all in all_in_list:
print(all)
结果为: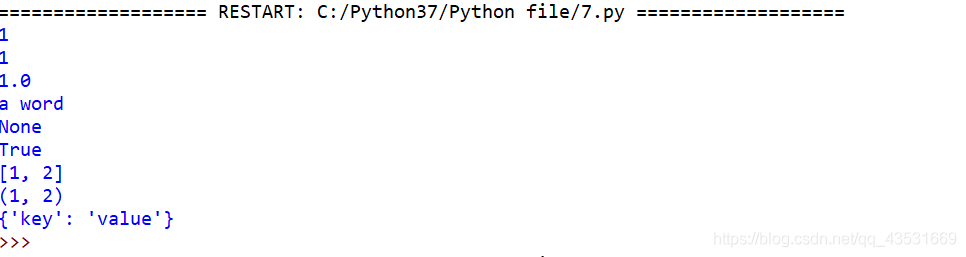
列表的增删改查:
对于数据的操作,最常见的是增删改查这四类。从列表的插入方法开始,输入:
fruit = ['pineapple','pear']
fruit.insert(1,'grape')
print(fruit)结果为:
删除列表中元素的方法是使用 remove():
fruit = ['pinapple','pear','grape']
fruit.remove('grape')删除还有一种方法,那就是使用 del 关键字来声明:
del fruit[0:2]想替换修改其中的元素可以这样:
fruit[0] = 'Grapefruit'列表的索引与字符串的分片相似,同样是分正反两种索引方式,只要输入对应的位置就会返回给你在这个位置上的值:

用元素周期表来试验一下:
periodic_table = ['H','He','Li','Be','B','C','N','O','F','Ne']
print(periodic_table[0])
print(periodic_table[-2])
print(periodic_table[0:3])
print(periodic_table[-10:-7])
print(periodic_table[-10:])
print(periodic_table[:9])结果为:
如果要是反过来,想要查看某个具体的值所在的位置,就需要用别的方法了,否则就会报错,这是因为列表只接受用位置进行索引,但如果数据量很大的话,肯定会记不住什么元素在什么位置,那么有没有一种数据类型可以用人类的方式来进行索引呢?其实这就是字典,我们一起来继续学习。
2、字典(Dictionary)
字典这种数据结构的特征也正如现实世界中的字典一样,使用名称-内容进行数据的构建,在 Python 中分别对应着键(key)- 值(value),习惯上称之为键值对。
字典的特征总结如下:
字典中数据必须是以键值对的形式出现的;
逻辑上讲,键是不能重复的,而值可以重复;
字典中的键(key)是不可变的,也就是无法修改的;而值(value)是可变的,可修改的,可以是任何对象。
用下面这个例子来看一下,这是字典的书写方式:
NASDAQ_code = {
'BIDU':'Baidu',
'SINA':'Sina',
'YOKU':'Youku'
}字典中的键与值必须是成对的!
同时字典中的键值不会有重复,即便你这么做,相同的键值也只能出现一次:
a = {'key':123,'key':1234}
print(a)
字典的增删改查:
创建一个字典,继续使用前面的例子:
NASDAQ_code = {'BIDU':'Baidu','SINA':'Sina'}与列表不同的是,字典并没有一个可以往里面添加单一元素的“方法”,但是我们可以通过这种方式进行添加:
NASDAQ_code['YOKU'] = 'Youku'
print(NASDAQ_code)结果为:
列表中有用来添加多个元素的方法 extend() ,在字典中也有对应的添加多个元素的方法 update():
NASDAQ_code.update({'FB':'Facebook','TSLA':'Tesla'})删除字典中的元素则使用 del 方法:
del NASDAQ_code['FB']需要注意的是,虽说字典是使用的花括号,在索引内容的时候仍旧使用的是和列表一样的方括号进行索引,只不过在括号中放入的一定是字典中的键,也就是说需要通过键来索引值:
NASDAQ_code['TSLA']同时,字典是不能够切片的,也就是说下面这样的写法应用在字典上是错误的:
chart[1:4] # WRONG!3、元组(Tuple)
元组其实可以理解成一个稳固版的列表,因为元组是不可修改的,因此在列表中的存在的方法均不可以使用在元组上,但是元组是可以被查看索引的,方式就和列表一样:
letters = ('a','b','c','d','e','f','g')
letter[0]4、集合(Set)
集合则更接近数学上集合的概念。每一个集合中的元素是无序的、不重复的任意对象,我们可以通过集合去判断数据的从属关系,有时还可以通过集合把数据结构中重复的元素减掉。
- 集合不能被切片也不能被索引,除了做集合运算之外,集合元素可以被添加还有删除:
a_set = {1,2,3,4} a_set.add(5) #添加 a_set.discard(5) #删除5、数据结构的一些技巧
有很多函数的用法和数据结构的使用是息息相关的。前面我们学习了列表的基本用法,而在实际操作中往往会遇到更多的问题。比如,在整理表格或者文件的时候会按照字母或者日期进行排序,在 Python 中也存在类似的功能:
num_list = [6,2,7,4,1,3,5]
print(sorted(num_list))结果:
sorted 函数按照长短、大小、英文字母的顺序给每个列表中的元素进行排序。这个函数会经常在数据的展示中使用,其中有一个非常重要的地方,sorted 函数并不会改变列表本身,你可以把它理解成是先将列表进行复制,然后再进行顺序的整理。
- 在使用默认参数 reverse 后列表可以被按照逆序整理:
sorted(num_list,reverse=True)
推导式:
现在我们来看数据结构中的推导式(List comprehension),也许你还看到过它的另一种名称叫做列表的解析式,在这里你只需要知道这两个说的其实是一个东西就可以了。
现在我有10个元素要装进列表中,普通的写法是这样的:
a = []
for i in range(1,11):
a.append(i) #append函数会在数组后加上相应的元素下面换成列表解析的方式来写:
b = [i for i in range(1,11)]列表解析式不仅非常方便,并且在执行效率上要远远胜过前者,我们把两种不同的列表操作方式所耗费的时间进行对比,就不难发现其效率的巨大差异:
import time
a = []
t0 = time.clock()
for i in range(1,20000):
a.append(i)
print(time.clock() - t0, seconds process time")
t0 = time.clock()
b = [i for i in range(1,20000)]
print(time.clock() - t0, seconds process time")
得到结果:8.999999999998592e-06 seconds process time
0.0012320000000000005 seconds process time列表推导式的用法也很好理解,可以简单地看成两部分。红色虚线后面的是我们熟悉的 for 循环的表达式,而虚线前面的可以认为是我们想要放在列表中的元素,在这个例子中放在列表中的元素即是后面循环的元素本身。
为了更好地理解这句话,我们继续看几个例子:
a = [i**2 for i in range(1,10)]
c = [j+1 for j in range(1,10)]
k = [n for n in range(1,10) if n % 2 ==0]
z = [letter.lower() for letter in 'ABCDEFGHIGKLMN']字典推导式的方式略有不同,主要是因为创建字典必须满足键-值的两个条件才能达成:
d = {i:i+1 for i in range(4)}
g = {i:j for i,j in zip(range(1,6),'abcde')}
g = {i:j.upper() for i,j in zip(range(1,6),'abcde')}循环列表时获取元素的索引
现在我们有一个字母表,如何能像下图中一样,在索引的时候得到每个元素的具体位置的展示呢?
letters = ['a', 'b', 'c', 'd', 'e', 'f', 'g']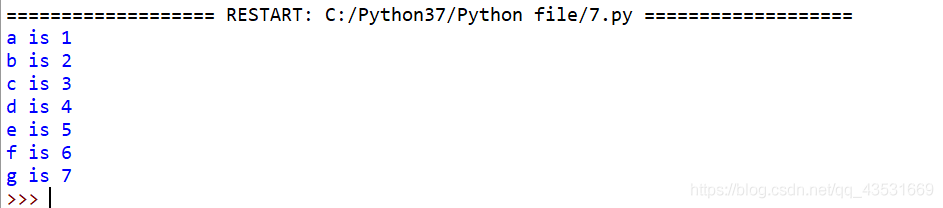
前面提到过,列表是有序的,这时候我们可以使用 Python 中独有的函数 enumerate 来进行:
letters = ['a', 'b', 'c', 'd', 'e', 'f', 'g']
for num,letter in enumerate(letters):
print(letter,'is',num + 1)如果同时需要两个列表应该怎么办?这时候就可以用到 zip 函数,比如:
a=[1,2,3]
b=['x','y','z']
for a,b in zip(str,num):
print(b,'is',a)
第七节:类
Python的类和C++/java 的类定义方法基本相同,但在声明对象是略有不同,Python把对象的声明进一步简化了。
例:
定义类:
class CocaCola:
formula = ['caffeine','sugar','water','soda']声明对象:
coke_for_me = CocaCola()调用:
print(CocaCola.formula)
print(coke_for_me.formula)
print(coke_for_you.formula)结果为:
>>> ['caffeine','sugar','water','soda']
>>> ['caffeine','sugar','water','soda']
>>> ['caffeine','sugar','water','soda']Python 支持直接使用类来调用方法,而java中必须是静态的方法才能使用类进行直接调用。
类的属性与正常的变量并无区别:
for element in coke_for_me.formula:
print(element)运行结果:
>>> caffeine
>>> sugar
>>> water
>>> soda和java里的类相同,Python的类有属性,方法等等…这里就不详细记录了。
例子:
class CocaCola:
formula = ['caffeine','sugar','water','soda']
def drink(self,how_much):
if how_much == 'a sip':
print('Cool~')
elif how_much == 'whole bottle':
print('Headache!')
ice_coke = CocaCola()
ice_coke.drink('a sip')运行结果:
>>> Cool~2、魔术方法:
Python 的类中存在一些方法,被称为”魔术方法”,_init_() 就是其中之一。
_init()是 initialize(初始化)的缩写,这也就意味着即使我们在创建实例的时候不去引用 init_()方法,其中的命令也会先被自动地执行。_init() 的神奇之处就在于,如果你在类里定义了它,在创建实例的时候它就能帮你自动地处理很多事情——比如新增实例属性。在上面的代码中,我们创建了一个实例属性,但那是在定义完类之后再做的,这次我们一步到位:
class CocaCola():
formula = ['caffeine','sugar','water','soda']
def __init__(self):
self.local_logo = '可口可乐'
def drink(self): # HERE!
print('Energy!')
coke = CocaCola()
print(coke.local_logo)运行结果:
>>> 可口可乐_init_() 方法可以给类的使用提供极大的灵活性。试试看下面的代码会发生什么:
class CocaCola:
formula = ['caffeine','sugar','water','soda']
def __init__(self):
for element in self.formula:
print('Coke has {}!'.format(element))
coke = CocaCola()结果为:
除了必写的self 参数之外,_init() 也有自己的参数,同时也不需要这样obj.init()的方式来调用(因为是自动执行),而是在实例化的时候往类后面的括号中放进参数,相应的所有参数都会传递到这个特殊的 init_() 方法中,和函数的参数的用法完全相同。
class CocaCola:
formula = ['caffeine','sugar','water','soda']
def __init__(self,logo_name):
self.local_logo = logo_name
def drink(self):
print('Energy!')
coke = CocaCola('可口可乐')
print(coke.local_logo)结果为:
3、类的继承
python中类的继承也比java更加简洁。
例:
class CaffeineFree(CocaCola):
caffeine = 0 #覆盖
ingredients = [ #覆盖
'High Fructose Corn Syrup',
'Carbonated Water',
'Phosphoric Acid',
'Natural Flavors',
'Caramel Color',
]
coke_a = CaffeineFree('Cocacola-FREE') # 传入初始化参数
coke_a.drink()在新的类 CaffeineFree 后面的括号中放入 CocaCola,这就表示这个类是继承于 CocaCola 这个父类的, CaffeineFree 就成为了 CocaCola 子类。类中的变量和方法可以完全被子类继承,但如需有特殊的改动也可以进行覆盖。
4、类属性与实例属性
Q1:类属性如果被重新赋值,是否会影响到类属性的引用?
class TestA:
attr = 1
obj_a = TestA()
TestA.attr = 42
print(obj_a.attr)结果:
Q2:实例属性如果被重新赋值,是否会影响到类属性的引用?
class TestA:
attr = 1
obj_a = TestA()
obj_b = TestA()
obj_a.attr = 42
print(obj_b.attr)结果:
Q3:类属性实例属性具有相同的名称,那么 . 后面引用的将会是什么?
class TestA:
attr = 1
def __init__(self):
self.attr = 42
obj_a = TestA()
print(obj_a.attr)
解释:
如图所示, Python 中属性的引用机制是自外而内的,当你创建了一个实例之后,准备开始引用属性,这时候编译器会先搜索该实例是否拥有该属性,如果有,则引用;如果没有,将搜索这个实例所属的类是否有这个属性,如果有,则引用,没有那就只能报错了。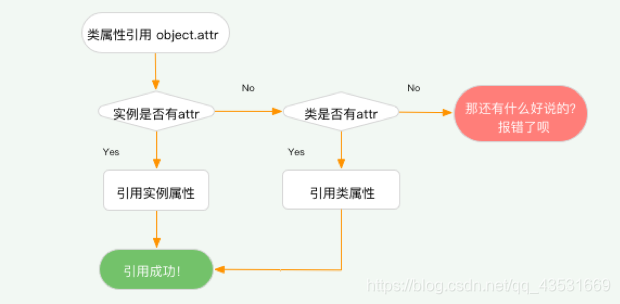
第七节:使用第三方库
如果用手机来比喻编程语言,那么 Python 是一款智能机。而海量的第三方库就是各种各样的app,丰富的第三方库为 Python 开发提供了极大的便利。
安装 pip:
在 Python 3.4 之后,安装好 Python 环境就可以直接支持 pip,你可以在终端/命令行里输入这句检查一下:
pip -version如果显示了 pip 的版本,就说明 pip 已经成功安装了。
使用 pip 安装库:
在安装好 pip 之后,以后安装库,只需要在命令行里面输入:
pip3 install PackageName注:PackageName 需要替换成你要安装的库的名称;如果你想安装到 python 2中,需要把 pip3 换成 pip。
如果你安装了 python 2和3两种版本,可能会遇到安装目录的问题,可以换成:
python3 -m pip install PackageName注:在存在多个 Python 版本的环境中,加上
python3 -m这种写法可以精确地控制三方库的安装位置如果你想安装到 python 2中,需要把 python3 换成 python
如果遇到权限问题,可以输入:
sudo pip install PackageName安装成功后会提示:
Successfully installed PackageName几个 pip 的常用指令:
pip install -upgrade pip #升级 pip
pip uninstall flask #卸载库
pip list #查看已安装库🆗,Python的基础学习就到这了,想要学好Python一定要多加练习!
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 2058751973@qq.com

